TextRank:文本排序
翻译自 TextRank 论文:
http://www.aclweb.org/anthology/W04-3252
前言
在这篇论文中,我们将介绍 TextRank — 一种基于图的排序模型,用于文本处理。说明这个模型如何成功应用在自然语言中。而且,对于关键字与文本抽取,我们提出了两个具有创造性的,无人监督的方法,并且结果显示与之前已经公布的结果相比是有利的。
1 介绍
以图为基础的排序算法像 HITS、PageRank 等已经在引用分析,社交网络以及互联网链式结构的分析上成功应用。在互联网搜索技术领域,这些算法被当作范式转换中关键的点。通过提供一种网页排序机制,这种机制依赖网站建设者们的集体知识而不是分析单个网页的内容。简单来说,以图为基础的排序算法是一种决定图内顶点的重要性的方法。通过考虑全局的信息而递归的计算整个图,而不是依赖局部特定顶点的信息。
可以将类似的思路应用到从自然语言文档中抽取词典跟语义图。所以基于图的排序模型可以广泛的应用到自然语言处理的应用当中。从整个文本中抽取出来的知识用于本地排序/选择做决定。这种面向文本的排序方法能够应用于构建自动化抽取关键短语,抽取摘要以及消除字的歧义等任务。
在这篇论文中,我们介绍 TextRank,基于图的排序模型,用于从自然语言文本中抽取图。我们调查并计算了包含了两种语言处理任务的 TextRank 应用,该任务包含了无监督的词和句子的抽取。并展示了 TextRank 与在这块领域中顶级系统所获得的结果。
2 TextRank 模型
以图为基础的排序算法本质上是决定图中顶点重要性的方法,基于全局信息的递归从整个图中获取。这个基本想法的实现是通过基于图的排序模型,就是投票或者推荐。当一个顶点指向另一个顶点,也就是说这个顶点向另外的顶点投了一票。一个顶点的得票数越多,它的重要性越高。而且,顶点投票的重要性决定了投票本身的重要性,这一点也被排序模型所考虑。因此,一个顶点的分数基于给它的投票,以及给它投票的顶点的分数所决定的。
一般地,让 $ G=(V, E) $ 来表示有向图。$V$ 表示顶点的集合,$E$ 表示边的集合。其中 $E$ 是 $ V \times V$ 的子集。对于给定的顶点 $V_i$,让 $ In(V_i) $ 表示指向 $V_i$ 的集合。让 $ Out(V_i) $ 表示 $V_i$ 指向的顶点的集合。定点 $V_i$ 的分数定义如下: \(S(V_i) = (1 - d) + d * \sum_{j \in In(V_i)} \frac{1}{\left\lvert Out(V_j)\right\rvert}S(V_j)\)
d 是一个阻尼系数,它的值在 0 ~ 1 之间。它的作用是将一个顶点跳到另一个随机顶点的概率整合到模型中。基于图的排序算法是随机冲浪模型的实现,用户随机的点击一个链接的概率为 d,那么跳到一个全新的页面的概率为 1 - d。d 的值经常被设置成 0.85。这个值也被用于我们的实现中。
给图的每一个节点给定一个随机的值,不断的迭代计算,直到到达给定的阀值。当算法开始运行,每一个顶点的分数代表其在图中的重要性。在完全运行完 TextRank 之后,最终得到的值不会受到初始值的影响,仅仅是收敛迭代的次数可能不一样。
有一点非常重要的是,虽然 TextRank 是基于 Google 的 PageRank,其它的基于图的排序算法像 HITS,Positional Function,但是可以轻易的被整合到 TextRank 中。
2.1 无向图
虽然传统的都是应用于有向图,但是一个递归的,基于图的排序算法也可以被应用于无向图,在这种情况下,一个顶点的入度就等于这个顶点的初度。对于连接松散的图,边的数量与顶点的数量成比例,无向图趋向更加平稳的收敛曲线。
图 1 绘制了随机生成的 250 个顶点与 250 个边的图的收敛曲线,它的收敛阀值是 0.0001。随着图的连接增加(例如:大量的边),在几次递归之后,收敛就可以达到。无向图与有向图的收敛曲线几乎是重合的。
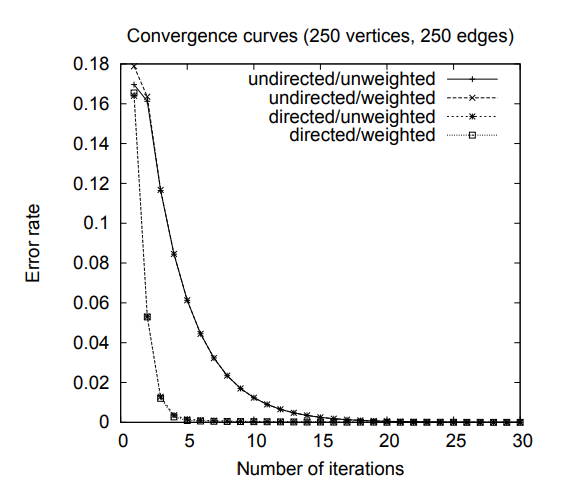
图 1:基于图的排序的收敛曲线:有向 / 无向图,有权 / 无权图,250 个顶点,250 条边。
2.2 有权图
在实际的上网场景下,一个页面包含大量或者部分其它页面的链接这个是不常见的。因此 PageRank 的定义,基于图的排序是在假设无权图的基础上。
但是,在我们的模型中,图的构建是通过对自然语言文本的抽取,所以在两个顶点之间可能包含大量或者部分其它页面的链接。所以,将两个顶点 $V_i$ 和 $V_j$ 之间权重 $w_{ij}$ 添加到连接两个顶点的边上,作为连接“强度”融入模型可能是有用的。
因此,我们介绍一个新的公式用于基于图的排序,并且考虑到边的权重用于计算顶点的分数。注意,可以定义一个相似的公式用于顶点权重的整合。 \(WS(V_i) = (1 - d) + d * \sum_{V_j \in In(V_i)} \frac{w_{ji}} {\displaystyle \sum_{V_k \in Out(V_j)} w_{jk}} WS(V_j)\) 图 1 绘制的收敛曲线来自 2.1 节相同的样本,边增加了 0-10 之间的随机权重。尽管顶点最终的分数与无权重的相比有不同的重要性,但是收敛的迭代次数与收敛曲线的形状几乎相似。
2.3 文本图
为了让基于图的排序算法应用到自然语言文本,我们需要构建一个能够代表文本的图,使单词或者文本实体相互之间进行有意义的连接。不同大小和特征的文本单元可以作为顶点添加到图中。例如:单词,搭配,整句或者其它的。相似的,这是应用去规定关系的类型,这些类型用于画出两个顶点之间的关系。例如:词典跟语义的关系,上下文重复等等。
不管什么类型和特性的元素添加到图中,基于图的排序算法应用在自然语言处理中包含如下几个步骤:
- 识别最好定义任务的文本单元,然后把他们当作顶点添加到图中
- 识别这些文本单元的关系,并根据这些关系画出它们的边。边可以是有向的也可以是无向的,有权的或者无权的
- 不断的递归迭代直到收敛
- 根据顶点最终的分数来排序。
接下来,我们将研究并计算 TextRank 应用对两种自然语言的处理任务,包含文本单元的排序:(1) 关键字抽取任务。选择的关键字代表给定的文本;(2) 句子抽取任务。识别文本中最重要的句子,可以用于构建摘要。
3 抽取关键字
抽取关键字的任务是自动去识别对文档描述最好的一组词。例如,关键字可以组成有用的条目为文档列表构建自动索引,能够被用于文本分类,能够抽取文档简明的摘要。甚至,自动识别文本中重要的词汇可以用于解决词汇的抽取以及构建特定领域的词典。
最简单的一种方法可能是根据频繁的引用去选择文档中重要的词。但是,这种方法经常被发现会导致结果差。目前这个领域最先进的方法是监督学习,基于词法与语法的规则,系统能够被训练自动去识别文本中的词。这个方法第一次被(Turney, 1999)提出,将参数化的启发式规则与基因遗传算法集成到系统(GenEx)中用于自动抽取文档中的关键词。另一个算法被(Frank, 1999)提出,将朴素贝叶斯学习策略应用于文档集中,在同一份数据集上能够提高被观察数据的结果(Turney, 1999)。Turney 与 Frank 都没有提及他们的系统,但是在关于精度上:GenEx (Turney, 1999) 在每个文档中抽取 5 个关键词,得到的精度为 29.0%。Kea (Frank 1999) 在每个文档中抽取 15 个关键字的精度为 18.3%。
最近,(Hulth, 2003)通过结合词法与语法的规则,在监督学习的系统中用于从摘要中抽取关键字,证明与比之前的结果相比,有了显著的提高。根据 Hulth 说法,从摘要中抽取关键字比从全文中提取更加广泛,因为网上大多数文档不适合做全文,但是可以作为摘要。Hulth 在 (Turney, 1999) 的提议的基础上,将部分词性信息结合到自动学习的过程中,并且通过将语言方面的知识去表示词,结果显示这个系统的准确性翻了一倍。
在这节当中,我们使用 TextRank 用于关键词的抽取,展示基于图的的排序模型在这个问题的处理上优于已经公布的结果。跟 (Hulth, 2003) 类似,我们通过抽取摘要中的关键词来评估算法。主要是为了跟她报告中的关键词抽取系统做明显的对比。注意,我们的系统没有文本大小的限制,同样的结果也可以应用于全文本。
3.1 TextTRank 用于关键词抽取
最终的预期结果是,词或者词组的列表能够代表给定的自然语言文本。因此,能够用来排序的单元是从文本中抽取出来的一个或者多个词汇单元的序列。任何两个词汇单元的之间关系都是一个潜在的有用的连接(边),能够被添加到两个相似的顶点中。我们通过两个单词出现的距离来控制共存关系:如果两个顶点相对应的词汇单元在一个最大为 N 个词的窗口中共存,则连接两个顶点。N 的值可以为 2 ~ 10。对于一个给定的文本,(Mihalcea, 2004)提出凝聚力指标,共存关系表达了两个语法元素之间的关系,类似于语义关系能够很好的消除词的歧义。
添加到图中的顶点可以通过语法过滤器来进行限制,只选择特定部分词性信息的词汇单元。例如,可以只在图中添加名字跟动词,因此基于它们的关系可以画出潜在的边。我们实验了各种语法过滤器,包括:所有开放类的词,名字和动词等等。只有名词跟形容词可以获得最好的结果,具体的详情见 3.2 节。
注:英语语法词性介绍:[英语单词的分类:封闭类,开放类和数词感叹词等其他类]
TextRank 的关键词抽取算法完全是不需要监督的。处理方式如下:
第一,将文本进行分词,并打上词性标签,预处理阶段需要使用语法过滤器。为了避免通过添加包含不止一个的词汇单元(ngram)的所有可能的组合序列而导致图的大小过度增长,所以对于多词关键词,我们最终在后处理阶段进行重新改造,只考虑将一个词作为候选词添加到图中。
第二,所有被添加到图中的词汇单元都会经过语法过滤器,在一个 N 个词的窗口中,共同出现的词汇单元将会通过边来连接。当图(无向无权图)被构建完成之后,每个顶点相关分数的初始值设置为 1。第二节的排序算法在图中经过几次迭代之后直到它收敛。一般阀值设置为 0.0001,需要 20 ~ 30 次迭代。
一旦在图中获取到了每个顶点的最终分数,每个顶点根据它们的分数进行反向排序。最终处理后保留排名中的前 T 个顶点。T 可以设置为任意固定的值,通常为 5 ~ 20 个关键字(例:(Turney, 1999) 在 GenEx 系统中限制抽取关键词的数量为 5)。我们使用一种更加灵活的方式,通过文本的大小来决定关键词的数量。我们实验中所用到的数据,包含相对较短的摘要。T 被设置为图中顶点数的三分之一。
在后处理的过程中,通过 TextRank 算法,所有被选中的词汇单元作为潜在的关键词都会在文本中被标记。相邻的关键词序列将会被当作为多词关键词。例如,在文本 Matlab code for plotting ambiguity functions 中,如果 Matlab 跟 code 被 TextRank 选中为潜在的关键词,由于它们相邻,所以它们被当作为一个关键词 Matlab code。
例:
Compatibility of systems of linear constraints over the set of natural numbers.Criteria of compatibility of a system of linear Diophantine equations, strict inequations, and nonstrict inequations are considered. Upper bounds for components of a minimal set of solutions and algorithms of construction of minimal generating sets of solutions for all types of systems are given. These criteria and the corresponding algorithms for constructing a minimal supporting set of solutions can be used in solving all the considered types systems and systems of mixed types.
TextRank 分配的关键词:
linear constraints; linear diophantine equations; natural numbers; nonstrict inequations; strict inequations; upper bounds
人为分配的关键词:
linear constraints; linear diophantine equations; minimal generating sets; nonstrict inequations; set of natural numbers; strict inequations; upper bounds
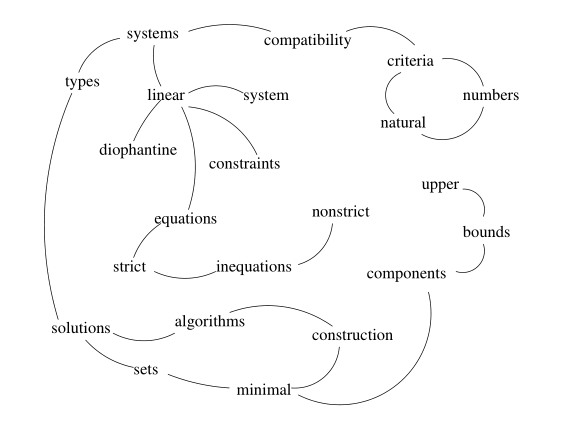
图二展示了从我们测试集中的一个摘要中构建的样本图。虽然摘要大小的范围只有 50 ~ 350 个字,平均只有 120 个字。我们故意选择了一个非常小的摘要来说明我们的方法。例如,TextRank 算法发现比较重要的词汇单元为(圆括号中表示分数):numbers (1.46),inequations (1.45),linear (1.29),diophantine (1.28),upper (0.99),bounds (0.99),strict (0.77)。注意这个跟仅仅依照词频来排序是不同的。对于同样的文本,使用频率的方式来进行排序,排在前几位的词汇单元为:systems (4),types (3),solutions (3),minimal (3),linear (2),inequations (2),algorithms (2)。所有其他的词汇单元的频次为 1,因此无法排序,所以只列出可以排序的。
3.2 评估
在实验中所用到的数据来自科学文摘的数据库,是由 500 个摘要组成的集合。以及相对应的手动分配的关键字。这些数据集跟 (Hulth, 2003) 在实验报告用到的数据集是一样的。这些科学文摘的数据来自计算机科学与信息技术的期刊论文。每一个摘要都包含了两组由专业索引器分配的关键词:指定的关键词受限制于给定的词典,没有指定的关键词由索引器自由的分配。我们使用 (Hulth, 2003) 的评估方法,以及没有指定的关键词集合。
在她的实验中,Hulth 使用了总共 2000 个摘要,分成了 1000 份进行训练。500 份用于开发,500 份用于测试。 由于我们的方法完全不需要监督,所以不需要训练/开发数据集。我们仅仅使用测试数据来评估我们的目标。
使用精确度,召回率,F 值来评估结果。在这个数据集中,最大的召回率小于 100%,因为我们的系统没有限制索引器对关键词的抽取。但是他们允许执行关键词的生成,最终导致关键词的结果没有清楚的出现在文本中。
处于对照的目的,我们使用了 (Hulth, 2003) 在报告中提到的最先进的抽取系统。很快,她的系统包含了一个监督学习的策略,尝试去学习怎样才可以做到最好的抽取文档中的关键词。通过查看四组特征来决定每一个候选的关键词:(1) 文档内的频率,(2) 集合中的频率,(3) 第一次出现时的相关位置,(4) 部分词性标注的序列。对于所有候选的关键词,这些特性从训练数据及测试数据中抽取。这些候选的关键词可以是: