solr 同义词处理
solr 笔记
虽然使用 SynonymFilter 可以处理同义词(例如:sea biscuit, sea biscit, seabiscuit),但是推荐在索引的时候处理同义词,因为在查询的时候处理同义词会有两个潜在的问题:
- Lucene QueryParse 会在任何文本进入 Analyzer 之前,在空白处进行标记。如果对关键词 sea biscit 进行搜索,Analyzer 会将这个关键词分成 sea、biscit,所以就不会知道他们会匹配一个同义词。
- 短语查询(Phrase searching)(例如:”sea biscit”)将会导致 QueryParse 将整个字符串传递到 Analyzer。但是如果通过配置 SynonymFilter 去扩展同义词,QueryParser 将会从 Analyzer 获取到一个 token 列表,并且会构建一个 MultiPhraseQuery,这样就达不到预期的结果。这是因为 Analyzer 可以表明两个 term 占据相同的位置,但是没有办法知道 phrase 与 term 占据同一个位置(这句话不知道翻译的对不对)。在这个例子中,MultiPhraseQuery 可能为 “(sea | sea | seabiscuit) (biscuit | biscit)”,不会匹配 “seabiscuit” 出现的文档。
即使你不担心多个词的同义词,idf 的差异性可以让同义词在索引期间进行处理。考虑下面这个例子:
- 一个 “text” 字段的索引,在查询期间使用 SynonymFilter 处理同义词:TV、Televesion,并且
expand = true - 成千上万个文档包含 “text:TV”
- 只有几百个文档包含 “text:Television”
对于查询 text:TV 将会拓展为(text:TV text:Television)。text:Television 具有相对较低的 docFreq,所以 “Television” 可能会比 “TV” 的得分更高。但是在索引期间处理,所有的文档都具有相同的 idf。
在 solr 中,通过同义词来进行搜索是很常见的场景。听起来很容易是吗?为什么查询 “dog” 返回的文档会包含 “hound” 与 “pooch”?甚至还包含 “Rover” 跟 “canis familiaris”。
其实,solr 对联想词的扩展并不是你所想的那样简单。经常会搬起石头砸自己的脚。
The SynonymFilterFactory
Solr 提供了 SynonymFilterFactory 用来处理包含了用逗号 (,) 分割的同义词的文本。你甚至可以选择是否相互的扩展你的同义词,或者指定一个方向拓展。
例如,”dog”, “hound” 与 “pooch” 都可以映射为 “dog | hound | pooch”,或者你可以指定 “dog” 可以映射为 “hound”,但是反过来不可以。或者你可以让它们都映射为 “dog”。这部分同义词的处理非常的灵活。
当你决定是要把 SynonymFilterFactory 配置在 query analyzer 还是 index analyzer 时会变得复杂起来。
Index-time vs. query-time
下面的图表很好的总结两者之间的不同之处。我们的问题是针对 solr,但是关于两者之间的选择可以应用到任何搜索系统。
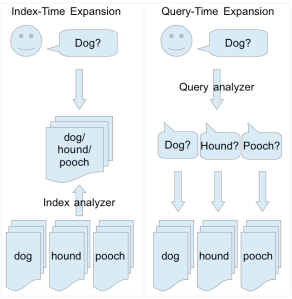
根据你的直觉判断应该将 SynonymFilterFactory 放到 query analyzer 中,因为在理论上,这有几个好处:
- 你的索引大小一致
- 你可以替换你的同义词而不需要重新索引
- 同义词可以立即生效而不需要重新索引
然而,根据 solr.SynonymFilterFactory,这是一种非常不好的做法。而且,你应该将 SynonymFilterFactory 放到 index analyzer 中。他们还解释了在查询时对同义词进行扩展的负面影响:
- 多词同义词,phrase query 不会有效
- idf 会提升稀有同义词的权重
- 多字同义词在查询不会被匹配
这就有点复杂了,所以我们需要逐步的解决这些问题
多词同义词,phrase query 不会有效
例如,”breast cancer” 的同义词:
breast neoplasm
breast neoplasms
breast tumor
breast tumors
cancer of breast
cancer of the breast
在对 SynonymFilterFactory 设置了 expand="true" 的情况,对于查询 “breast cancer” 将会变成如下形式:
+((breast breast breast breast breast cancer cancer) (cancer neoplasm neoplasms tumor tumors of of) breast the breast)
原文不是这样的分词,因为我认为他说错了
你希望它可以匹配包含 “breast neoplasms”,”cancer of the breast” 等等词语的文档。
但是,如果你做了 phrase query(例如:”breast canche” 用双引号括起来),你匹配到的将是包含了 “breast cancer breast breast” 诸如此类的文档。
事实证明,SynonymFilterFactory 并没有按照你所想的那样扩展你的多词同义词。如果我们用有限自动机来表示,你可能认为 solr 会建立像下面一样的关系图(忽略复数):
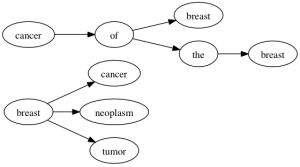
但是实际确实这样的:
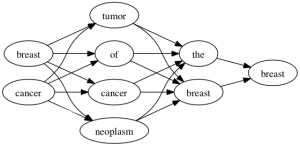
而只有包含连续四个词的文档才可以被匹配到。
类似的还有,DisMax 跟 EDisMax 中的 mm 参数也不会符合预期的效果。在上面的例子中,设置 mm=100% 则必须匹配到 4 个词。
+((breast breast breast breast breast cancer cancer) (cancer neoplasm neoplasms tumor tumors) breast breast)~4
idf 会提升稀有同义词的权重
即使你没有多字同义词,Solr 文档中提出第二个不在查询时做拓展的原因:idf 加权。考虑 “dog”、”hound”、”pooch” 这个例子,对于其中任何一个词进行查询都会被映射成如下结果:
+(dog hound pooch)
因为 “hound” 与 “pooch” 不是常见的词,所以包含这两个关键词的文档的权重将会被提升。这将会给你的用户造成错觉,为什么他们搜索 “dog”,但是包含这两个关键词的文档会显示在前面。而在索引时扩展则避免了这个问题,对于这三个词,它们的 idf 值是一样的。
多字同义词在查询不会被匹配
最严重的情况是,无论你通过什么方式来进行分词,查询的时候 SynonymFilterFactory 将不会匹配多字同义词。这是因为在 SynonymFilterFactory 做转换之前,分词器已经对输入的词进行了分解。
例如,对于查询 “cancer of the breast” 将会被 StandardTokenizationFactory 分解成 [“cancer”, “of”, “the”, “breast”]。而且只有单个词会通过 SynonymFilterFactory。
翻译自:《apache-solr-ref-guide-6.3》
Synonym Filter
这个过滤器用来做同义词映射,每一个词都会去同义词列表中查找是否匹配,如果找到了,则将当前词用同义词取代。新词的位置跟原词一样。
Factory class: solr.SynonymFilterFactory
参数:
synonyms:(必须) 包含同义词列表的文件路径,文件中的同义词一行一个。在 solr 默认格式 (参考 format 参数) 的情况下,空白行与以 “#” 开头的行会被忽略。它的值可以是绝对路径,也可以是相对 config 文件夹的路径。有以下两种方式去指定同义词的映射关系:
- 用 “,” 分隔的词列表。如果一个词匹配了列表中的任何一个词,那么所有在列表中的词都会被替换,也包括原词。
- 用 “=>” 分隔的词列表。如果一个词匹配了分隔符左边的任何词,那么分隔符右边的词将会被替换。但是原词不会被替换,除非原词也出现在了右边。
ignoreCase:(可选,默认 fasle) 如果为 true,同义词将会区分大小写。
expand:(可选,默认 true) 如果为 true,就会映射所有的同义词的,不然只会映射列表中的第一个。
format:(可选,默认 solr) 控制同义词怎么被解析。solr 表示 SolrSynonymParser,wordnet 表示 WordnetSynonymParser,你可以通过继承 SynonymMap.Builder 来自定义解析类。
tokenizerFactory:(可选,默认 WhitespaceTokenizerFactory) 使用分词器工厂来解析同义词。前缀 “tokenizerFactory.” 可以提供一些初始化参数去初始化分词器工厂类。如果指定了 tokenizerFactory,analyzer 可以不指定,反之亦然。
analyzer (可选,默认 WhitespaceTokenizerFactory) 使用分析器工厂来解析同义词文件,如果指定了 analyzer,那么 tokenizerFactory 可以不指定,反之亦然。
假设有一个包含同义词的文件叫做 mysynonyms.txt:
couch,sofa,divan teh => the huge,ginormous,humungous => large small => tiny,teeny,weeny
Example1:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" />
</analyzer>
输入:”teh small couch”
分词后进去过滤器:”teh”(1), “small”(2), “couch”(3)
输出:”the”(1), “tiny”(2), “teeny”(2), “weeny”(2), “couch”(3), “sofa”(3), “divan”(3)
Example2:
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory" />
<filter class="solr.SynonymFilterFactory" synonyms="mysynonyms.txt"/>
</analyzer>
输入:”teh ginormous, humungous sofa”
分词后进去过滤器:”teh”(1), “ginormous”(2), “humungous”(3), “sofa”(4)
输出:”the”(1), “large”(2), “large”(3), “couch”(4), “sofa”(4), “divan”(4)